Have you ever wondered how artificial intelligences can understand language? For decades, AI has been associated with technical and scientific topics such as weather prediction, medical diagnosis, object recognition in images, and more. All these issues are related to quantifiable measures, numbers. What made it easier for AI to understand language?
In this post you will be able to understand the concepts and methods that allowed AI to understand language with mathematics, from an intuitive and concept perspective, noting that the concepts have a more advanced mathematical basis than the one described here.
NLP, the ancestor of LLM
Much is said today about long language models (LLMs) and their ability to respond, summarize and translate content with ease. However, these capabilities did not come out of nowhere, there was a progressive advance in the field of natural language processing (NLP) that gave life to solutions that are now a daily habit such as internet search engines, the translation of texts into various languages, spell checkers and many others. It was the advancement in this discipline that created the mathematical foundations of the LLMs, below, we will explain the first ways of understanding language with mathematical structures.
Representing Words in Structures
NLP techniques start from a common base, take a group of texts such as books, news or messages, then process them in several stages and generate new information. The group of texts is called Corpus, we could talk about studying 100 books with hundreds of pages, 5,000,000 words in sequence and a vocabulary of 100,000 unique words.
By entering these words into structures, each structure provides a way to calculate numbers on them. The following statements describe basic structures for ordering vocabularies:
Indexes
It consists of ordering words in a list according to an order. Clear examples are:
Alphabetical index: Sorted from A to Z, it helps to search for each word in a list.
Frequency index: ordering words according to the number of words that are repeated in the texts, helps to find common words and unique words.
The problem with indices is that they do not contribute to understanding concepts and comparing some indices does not add meaning, for example: the index of good is greater than bad, but the index of pleasant is less than unpleasant, when they are ordered in alphabetical order.
Taxonomies
This structure is a hierarchical order of words according to a classification, they are useful to represent qualities, feelings, themes, synonyms and categories. Example:
- Good
- Pleasant
- Enjoyable
- Satisfactory
- Bad
- Ungrateful
- Uncomfortable
- Insufficient
This structure helps to represent concepts according to some meaning, but it has challenges, a subject or an official source must provide the classification. In addition, it is not able to respond to new words, also called Out-of-vocabulary (OOV), if there are new words, a subject must classify them.
Engrams
Engrams or N-grams are structures that represent sequences in a structure of length N, an N-gram with N = 3 is 3 words in sequence. Example In the sentence: “The cat meows on the roof” we have the following engrams:
- (the, cat, meows)
- (cat, meows, on)
- (meows, on, the)
- (on, the, roof)
Applying this technique to a large corpus would create a list of all the sequences of 3 words, after that the frequency of each n-gram can be counted and thus know how frequent a simple phrase such as “the cat meows” is in contrast to “the cat barks” or “the cat cackles”.
The contributions of n-grams to the mathematics of language are several, we can highlight 2 key tasks:
The probability of the next word: by ordering all the n-grams of length 3 that follows the equation (“the”, “cat”, x3) the next word (x3) can be proposed according to its frequency or probability, some results would be: meow, play, bite, run. This frequency will depend on how many times the phrase occurred in the corpus of texts that generated the n-grams.
Context of the words: putting a word in the middle of the engram and looking for the n-grams that contain it ordered by frequency helps to understand in which contexts the word is repeated. The engram equation (x1, “good”, x2, x3) can find contexts such as “it’s good to help”, “it’s good to know”.
The n-gram provides a strong basis for the calculation of probabilities in words, but it has its drawbacks, too many engrams are generated when processing an abundant amount of texts, the length of the engram conditions the quality of answering the next word and both the calculations and the storage of this information structure is expensive.
Fortunately, word vectors found a more efficient way to store information and process calculations.
Vectors
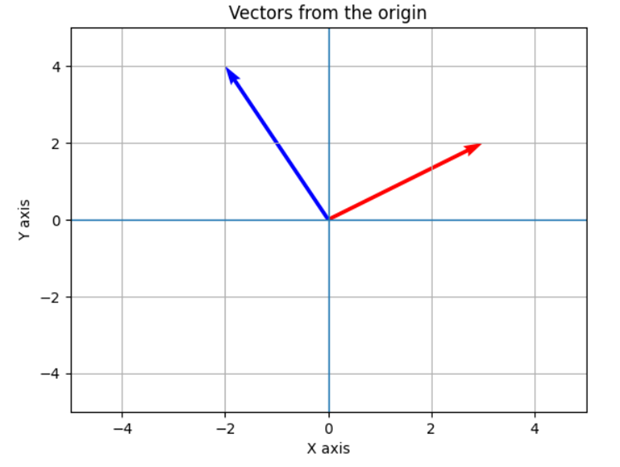
In mathematics vectors are known as coordinates in a Cartesian plane, in the figure we see a vector of 2 dimensions (x and y coordinates).
There can be vectors of more dimensions, even so, their mathematical properties are maintained, within them we can highlight the direction, magnitude, Euclidean distance, angles and point product.
It is common to use vectors in physics fields to represent forces, velocities, and acceleration. In geography it allows drawing planes, areas and distances. While in the study of climates, vectors can represent wind forces, humidity, density and numerous properties.
Representing words in vectors
Suppose we draw the word ‘good’ and ‘bad’ on a 2-dimensional vector plane, the result looks similar to the image below:
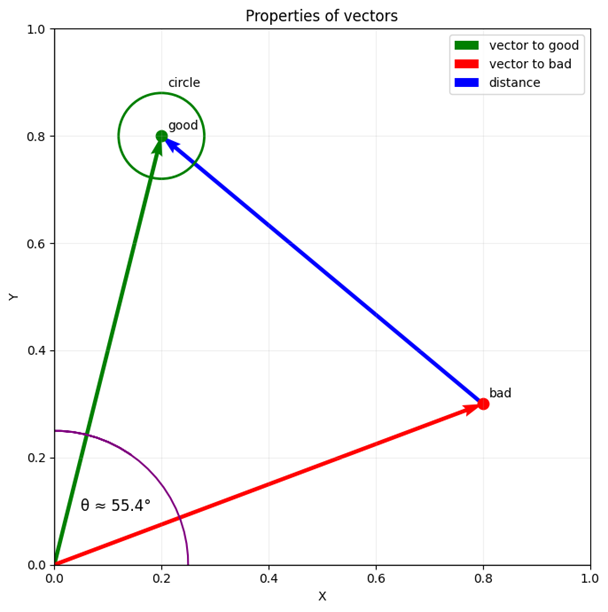
With this image we can notice calculable properties among them:
- Magnitude: the length of each arrow
- Direction: this is where the vector is pointing, it is clear that the green and red arrows point in different directions.
- Angle: The angle between vectors is calculable and helps to compare direction.
- Nearby area: when drawing a circle at a point as the center, we can look for other points near it.
The expectation of creating word vectors is that each word has a unique position and similar or close words in contexts can match in the same area, in the image below you can see a representation of this.
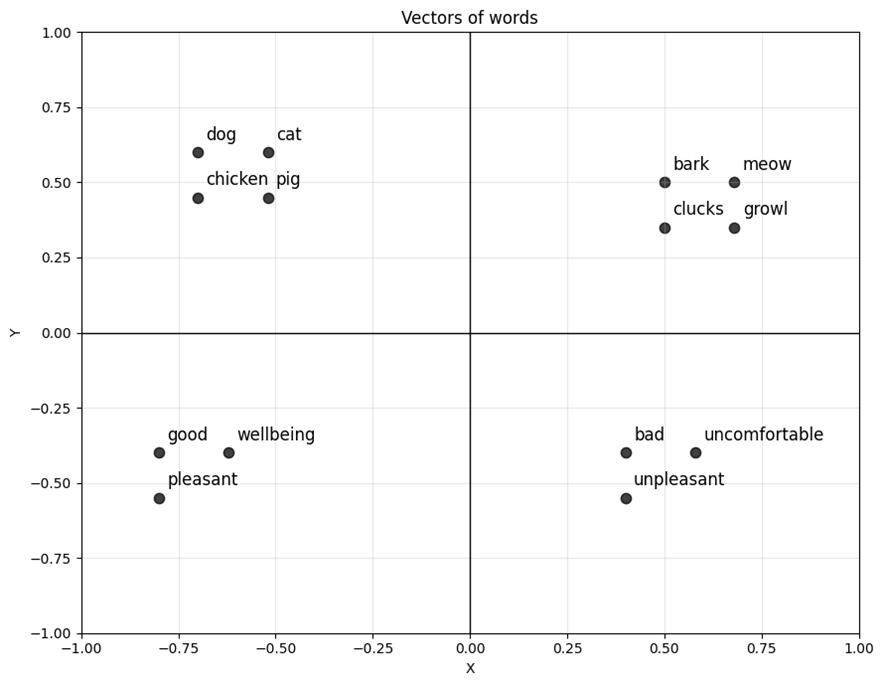
If it is possible to meet this expectation, it is possible to create a geographical plane of words that performs operations between them and allows more complex probability calculations to be made.
What do word vectors look like?
The explanation of vectors with a plane in 2 dimensions helps a lot to the intuition of mathematics, it is seen as a map, however, in order to give more descriptive and semantic properties to words, vectors of more dimensions are required. A possible representation of this is seen in the figure below with a vector length of 8 for each word in the sentence.

This table is more like a real vector used by an AI that could have 100 dimensions, this is called a hyperplane. It is difficult to find a meaning from the human eye when viewing such a table, however, the AI understands it as if it were a map and uses the same algebra properties described in 2 dimensions.
How are word vectors created?
The task of taking a word and creating its vector is a complex process that reads a large corpus of text and looks for patterns for each unique word in the vocabulary, taking advantage of its properties of sequences, contexts, frequency, semantics, and other elements. Different companies and institutions created their own algorithms to generate this result:
- Word2vec – Google – 2013
- GloVe – Stanford – 2014
- fastText – Facebook – 2015
- ELMo – Allen Institute for AI (AI2) – 2018
Each algorithm has its own complexity and can include n-grams or neural networks to create the vectors.
Predicting the next word
In a previous example it was said that n-grams can calculate the probability of the next word, starting with 2 words to answer a third. In contrast, word vectors do not save the sequence, they only put the words in a vector space or map, in an orderly way.
This is where LLMs and their deep neural networks apply a role of learning the sequences of words, from input and output examples, they can understand how the words are related in sequence. Examples can be of various types: questions and answers, language 1 to language 2, task to result, among others. The process is complex, what is relevant for the article is that word vectors are the data input for the neural networks of LLMs.
Some LLM models also have position vectors at the output of the networks, these vectors deliver the words with their position in a sentence to add coherence to the output sequence.
In order to represent this learning in the simplest way possible, let’s consider the following image as a vector map of words, where we want to deliver an animal as input, and obtain the sound of the animal as output.
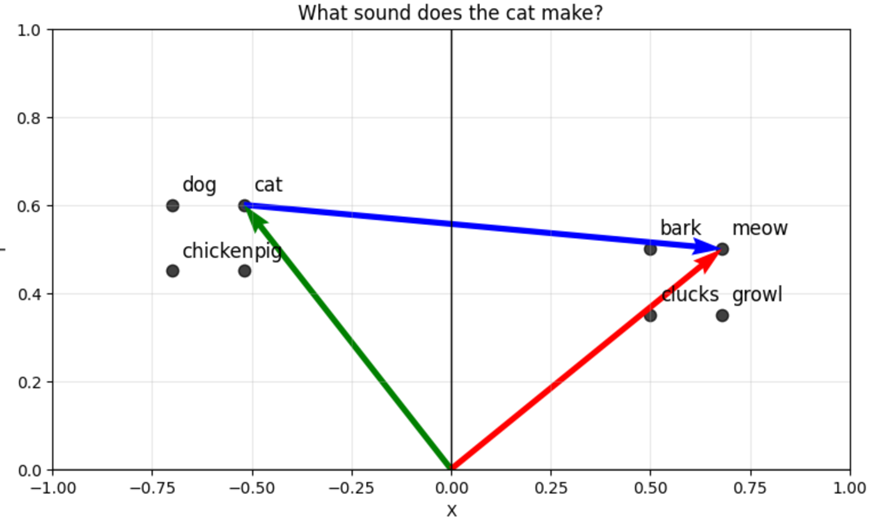
The green input is a clear position in space, and the red output is on the other side of an axis. To get from the input to the output there is a mathematical operation involved, this operation can be represented as the multiplication and/or addition of parameters to the input coordinate. In the figure, the blue arrow is an addition to the x coordinate and a subtraction to the y coordinate of the input (cat coordinate). Inferring the value of parameters is an operation known as regression and is the basis of neural networks with supervised learning.
Conclusions
By way of summarizing the above, we can say the following
- Words have a meaning according to their context in a group of texts, also called a corpus.
- There are various structures to represent words, some provide meaning and others provide probabilities.
- Word vectors provide a means of positioning words on a map or hyperplane, this helps advanced mathematics.
- Thanks to this, the relationships between words can be learned with neural networks, which is the basis of AI and LLMs.
I hope the article generates interest in understanding the inner workings of AI, the examples have been a simplification of various complex mathematical processes. In real programs they apply this on a large scale. This simple and visually intuitive article seeks to isolate a part of the process to make it more assimilable for more audiences.
